查询语句怎么执行的
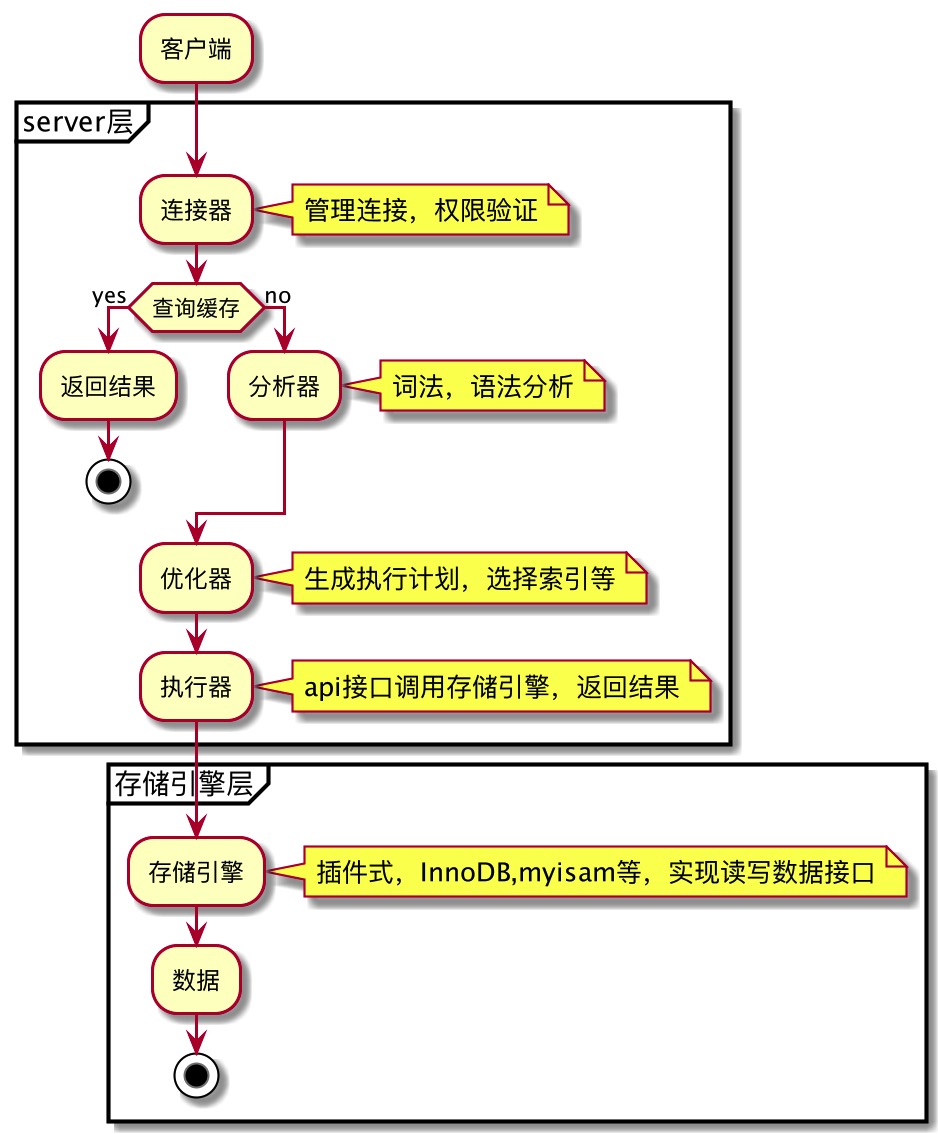
连接器
MySQL服务器和MySQL客户端连接使用tcp协议。如果认证通过,连接器会到权限表中查出账号拥有的权限,以后所有的权限判断都是基于此时查出的权限。也就是说用户连接成功后,在修改用户权限,是对已成功的连接不会成效的。
连接建立成功后,如果长时间没有操作,连接器会自动断开连接。断开连接的时间是由wait_timeout控制的,默认值是8小时。
查询缓存
MySQL查询缓存保存查询返回的完整结构。当查询命中该缓存时,MySQL会立刻返回结果,跳过了解析、优化和执行阶段。 查询缓存系统会跟踪查询中涉及的每个表,如果这些表发生了变化,那么和这个表相关的所有缓存数据都将失效。
当查询语句中有一些不确定的数据时,则不会被缓存。例如包含函数NOW()或者CURRENT_DATE()的查询不会缓存。包含任何用户自定义函数,存储函数,用户变量,临时表,mysql数据库中的系统表或者包含任何列级别权限的表,都不会被缓存。
分析器
对 SQL 语句做解析,词法分析出”select” ,要使用的表名,字段等等。语法分析,看sql语句是否满足mysql 的语法。
优化器
决定使用哪个索引,怎么join表等等,生成执行计划
执行器
开始执行的时候,要先判断一下你对这个表 T 有没有执行查询的权限,如果没有,就会返回没有权限的错误。如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
更新语句怎么执行的
更新语句 照样会走 查询语句怎么执行的 这套流程。于查询语句会查询缓存不同的是,更新语句会让对应表的缓存时效。另外更新语句还需要写2个日志,redo log(重做日志)和 binlog(归档日志).
mysql不是每次数据更改都立刻写到磁盘,而是会先将修改后的结果暂存在内存中,当一段时间后,再一次性将多个修改写到磁盘上,减少磁盘io成本,同时提高操作速度。也就是 先写日志,在写磁盘 WAL(Write-Ahead Logging)
redo log
redo log 是innoDB存储引擎实现的,采取循环写的模式。InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么这块“粉板”总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写.
当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做.
binlog
binlog 是MySQL server实现的,所有的存储引擎都使用。以追加写的方式记录。它记录了所有的 DDL 和 DML 语句(除了数据查询语句select、show等),以事件形式记录。binlog 的主要目的是复制和恢复。
为什么有了redo log 还需要binlog?
1.redo log的大小是固定的,日志上的记录修改落盘后,日志会被覆盖掉,无法用于数据回滚/数据恢复等操作。
2.redo log是innodb引擎层实现的,并不是所有引擎都有。
执行过程

redo log 写成功后状态为prepare ,只有binlog也写成功后,状态变成commit。这个有点 “事物”的味道。这就是”两阶段提交”。
如果不使用“两阶段提交”,就有可能导致redo log 和 binlog 记录的数据库状态不一致,那么数据库的状态就有可能和用它的日志恢复出来的库的状态不一致。
日常开发中也有可能会用到”两阶段提交”。
参考 丁奇 ·《MySQL实战45讲》
参考 《高性能MySQL》